

Mid-October 2022 PostgreSQL v15 was released with some great new features. Since February, minor release PostgreSQL v15.2 became available to make it ever more stable.
In this release we saw improved performance and reduced memory consumption of in-memory sorts by using generation memory context and reduced function call overhead.
Speed in sorting is important because it’s a widely used mechanism in a Relational Database Management System (RDBMS), most used or known is the ORDER BY clause in SQL statements.
But sorting is also needed:
-
- with GROUP BY in queries
- with WINDOW FUNCTIONS with a PARTITION BY
- when aggregate functions are used in combination with an ORDER BY clause
- executing queries with an execution plan containing a MERGE JOIN
- in UNION queries and when using DISTINCT
The widely used FDWs (Foreign Data Wrappers) can commit now in parallel on all foreign servers involved in local transaction, improving performance of distributed PostgreSQL clusters.
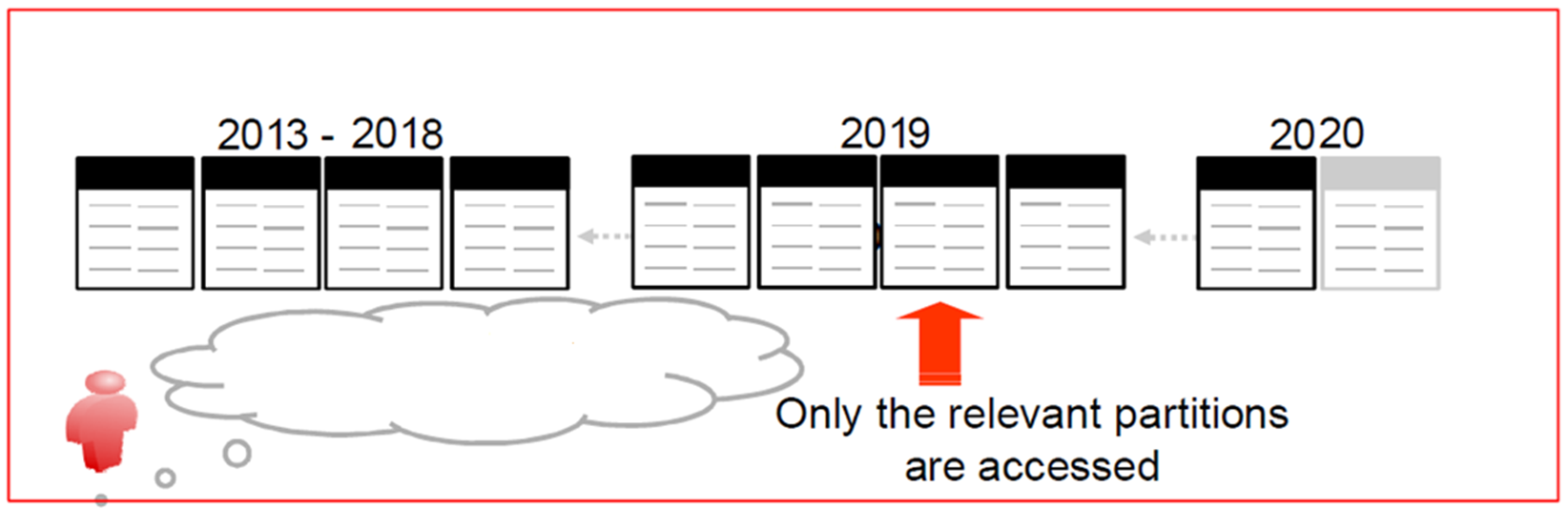
The declarative PARTITIONING feature of tables was introduced in PostgreSQL v10, which was released in 2017. Since then, much functionality has been added and improved in PARTITIONING, like planning time for statements where only a few partitions are relevant. Next to that, performance is improved by avoiding the need to sort.
A quick recap, PostgreSQL offers built-in support for the following forms of partitioning:
-
- List Partitioning
Partition your data by REGION, an example:
- List Partitioning
- Range Partitioning
Partition your INVOICES by INVOICE_DATE, e.g.:
- HASH Partitioning
In PostgreSQL v11 came HASH partitioning that distributes the rows based on the hash value of the partition key.
Next to the default partition, indexes are automatically created on the child tables. When enabling PARTITIONWISE AGGREGATION the query planner pushes down to the partition level resulting in faster queries because of better parallelism and improved lock handling.
Also speeded up RECOVERY and REPLAY by prefetching needed file contents, by looking ahead in the WAL and trying to initiate asynchronous reading of referenced data blocks not yet cached.
Aggressive VACUUMING, sounds bad, but it isn’t. 😉
Before PostgreSQL v15, vacuum was using the FreezeLimit value cutoff to freeze tuples. Now this value can be set to the oldest extant XID remaining in the table, reducing vacuuming for certain workloads.
Next to other optimizations, here are some New Features:
- Support for the SQL MERGE command
- Handles inserts, updates and deletes in one single transaction.
- Selective publication of the contents of tables within logical replication publications, through the ability to specify column lists and row filter conditions, and support is added for prepared transactions to the built-in logical replication.
- Support for Zstandard/Zstd COMPRESSION on server side used by pg_basebackup
- Next to that the targets can by specified using -t <target> (client or server).
- Server- or Client-side compression using options gzip, LZ4 or Zstd.
- Also, Full Page Writes can be compressed in WAL.
- WAL archiving can be achieved via loadable modules.
- Structured server log using the JSON
- STATISTICS are stored in shared memory, reducing writes to temp files.
- Previous statistics are restored after shutdown and restart.
- EXTENDED STATISTICS can be recorded for a parent with all its children, resulting in improved queries.
Each new major release of PostgreSQL brings performance improvements, certainly in this release of PostgreSQL.
PostgreSQL v16 will be released end of 2023 with some improvements, related to:
- Logical Replication
- Allowing replications on same table by filtering on origins
- Apply in parallel
- Replication of sequences
- Logical replication based on Standby
- Replication of DDL
- Replication of LOBs
- SQL / JSON making it more standard compliant
- Asynchronous I/O allowing prefetching data and will improve system performance
- Direct I/O that will bypass OS cache in some cases and lead to better performance
- TDE and Transparent column encryption of particular columns
- HASH indexes, like unique and multi-column indexes
- VACUUMing and reducing WAL volume
- Incremental maintenance of Materialized Views
Zebanza and PostgreSQL … even in the wild they match well!
For more detailed information about PostgreSQL v15.2, contact us!



